 下载格隆汇APP
下载格隆汇APP
 下载诊股宝App
下载诊股宝App
 下载汇路演APP
下载汇路演APP
 社区
社区
 会员
会员
AI竞赛场上,海外巨头“厮杀”甚是激烈,国内大模型的进化也上演加速度。
5月9日,在北京举办的阿里云AI智领者峰会上,通义千问2.5正式发布。
此次,大模型能力实现大升级,性能全面赶超GPT-4 Turbo,成为“地表最强”的中文大模型。
赶超GPT-4
阿里云表示,相较于通义千问2.1版本,通义千问2.5的理解能力、逻辑推理、指令遵循、代码能力分别提升9%、16%、19%、10%。
对比GPT-4,在中文语境下,通义千问2.5在文本理解、文本生成、知识问答&生活建议、闲聊对话,以及安全风险等多项能力上均全面赶超。
在这轮竞争激烈的AI大模型浪潮里,这是国产大模型首次取得这样的成绩。

在长文本处理方面,通义千问2.5支持单次最长1000万字文档的处理,并且同时能够处理多达100个文档。
通义千问还支持对PDF、Word、图表等多种不同格式的文档进行处理,满足了用户多样化的需求。

除了通义千问2.5之外,阿里云还发布了一组新“成绩”。
阿里云首席技术官(CTO)周靖人在会上表示,通义大模型已经通过阿里云服务企业超过9万家,通过钉钉服务企业超过220万。
通义千问API日调用量已破亿,通义开源模型的累计下载量突破700万次。
另外,通义落地应用的进程也在加速,目前已经涉足PC、手机、汽车、航空、天文、矿业、教育、医疗、餐饮、游戏、文旅等多个领域。
其中,小米旗下的“小爱同学”也与阿里云通义大模型达成合作,并将在小米汽车、手机等多类设备落地。

另外,通义灵码宣布推出企业版。通义灵码是国内用户规模第一的智能编码助手,基于SOTA水准的通义千问代码模型CodeQwen1.5研发,插件下载量已超350万。
通义千问最新开源的1100亿参数模型——Qwen1.5-110B也收获了最佳成绩。
在MMLU、TheoremQA、GPQA等基准测评中,该模型超越了Meta的Llama-3-70B,成为开源领域最强大模型。
峰会上,阿里云强调要成为“AI时代最开放的云”,通过开放的算力平台、开源的自研模型、优质的模型服务,帮助客户抓住大模型时代的机遇。
国产大模型迈入核心竞技场?
去年4月,通义千问正式亮相。
当时,阿里云就曾表示,要让中国整体的AI能力有全方位的提升。
“未来所有软件都值得接入大模型升级改造,我们将开放通义千问的能力,为每一家企业打造自己的专属GPT(一种预训练的语言模型)。”
恰逢一周年之际,通义千问大模型的进阶,也意味着国产大模型再上一层楼。
自2022年ChatGPT发布以来,AI大模型在全球范围内掀起了有史以来最大规模的人工智能浪潮。
可以说,过去的一年,这个圈子是“要多卷有多卷”。
当下,OpenAI、谷歌、微软等猛“砸钱”不断革新着自家产品。除了海外巨头“你追我赶”之外,国内大模型也是“浑身使劲”紧追其后。
据SuperCLUE团队研究数据,国内大模型的进展大致分为三个阶段,即准备期、成长期、爆发期。
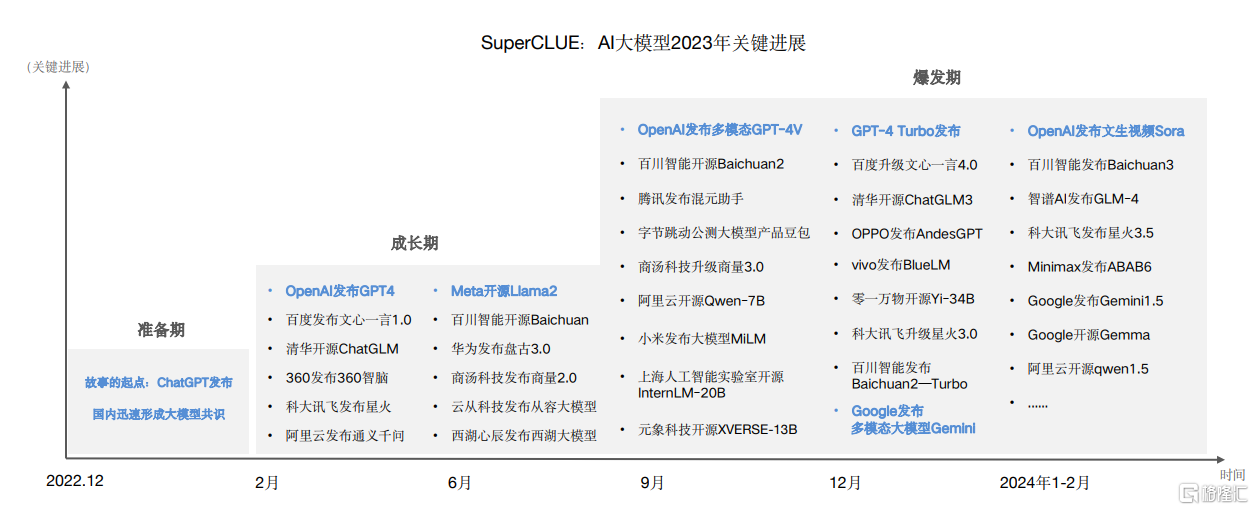
目前,除了阿里通义千问、百度文心一言、华为盘古等科技大厂“马不停蹄”加紧研发国产大模型外,还有复旦MOSS、中科院紫东太初、初创黑马-月之暗面的Kimi等陆续脱颖而出。
从行业发展来看,银河证券表示,未来通用AI大模型领域可能会更加集中在头部厂商,更多厂商需要向行业专业化转型,垂直类AI大模型、端侧AI大模型将是未来主战场,市场空间广阔。建议关注上游算力基础设施相关机会,国产算力产业链及生态伙伴相关机会,以及下游应用端领域。
华泰证券此前也表示,国产优质大模型能力持续进阶,有望推动应用快速发展,投资关注三条逻辑线。
1)视频/语料素材库逻辑,大模型需优质训练素材投喂,素材价值有望放大;
2)应用接入Kimi及其他优质大模型,其长文本理解及处理能力,有望充分赋能在线阅读、教育、营销、电商等领域应用场景;
3)与其他优质国产大模型合作的公司,有望通过优质大模型提升主业。



